- Underwrite.In
- Posts
- The biggest blind spots in insurance underwriting today
The biggest blind spots in insurance underwriting today
Here’s how to detect them
Shen Pandi
October 31, 2025
Today, we are focusing on:
The unseen risks quietly entering underwriting models
How AI turns raw data into real-time early warning systems
What smart insurers are doing right now to stay ahead
See, the biggest risk in insurance today isn’t the one sitting in your claims data, it’s the one that hasn’t surfaced yet.
By the time it shows up in loss ratios or renewal trends, it’s already too late.
Traditionally, underwriting models depend on historical data like past claims, known exposures, and market averages. But today’s risks don’t follow those rules anymore.
In the past decade, cyber event frequency has doubled every 18 months.
Climate-driven losses are appearing in previously low-risk zones.
And macroeconomic volatility is compressing the reaction window for underwriters from quarters to weeks.
But by that point, the damage has already begun, whether it’s rising loss ratios, unusual claims clustering, or unexplained renewal drops.
The problem isn’t the lack of data. It’s that conventional models are built on retrospective data.
That’s why insurers are now turning to AI not as automation, but as anticipation, systems that can detect subtle pattern shifts, correlations, or anomalies before they register as claims.
What are the unseen risks in old underwriting models?
Here are some of the common pitfalls your team might miss:
Operational blind spots
One of the biggest blind spots in underwriting starts far earlier than pricing or exposure modeling, it begins at the submission stage.
Incomplete or poor-quality model submissions have been identified as the single largest barrier to validation timelines in financial institutions.
In fact, 76% of respondents in a McKinsey survey cited submission quality issues as a major obstacle in their model risk management processes.
In insurance, these gaps compound quietly: missing exposure fields, unstructured broker notes, inconsistent risk classifications, outdated third-party risk scores. Individually, they seem minor.
But spread across hundreds of submissions and multiple lines of business, they distort portfolio loss projections by 15-20% and delay model decisions by weeks.
This is where most underwriters think they have clarity, but the real blind spot is hiding in fragmented inputs that never flag themselves as a problem until losses start forming.
Emerging risk types
Cyber claims alone have grown by roughly 100 % over the past three years, while payouts surged 200% in the same period.
What makes this a blind spot for underwriting?
In the US and global insurance sector, 59% of breaches among the top 150 insurers were traced back to third-party attack vectors, far higher than most average sectors.
Put together, this means:
Models are using stale data (12-18 months lag is typical) while risk evolves weekly.
Emerging vectors (third-party exploits, new tech platforms, climate & cyber convergence) are not well represented in legacy tables.
Underwriters may appear to be assessing “safe” exposures, yet the data is shifting underneath them.
Market shifts
Sudden surges in gig-economy liabilities, exposure from decentralized finance instruments, or regulatory shifts in ESG compliance can introduce subtle correlations between risks that legacy models simply aren’t designed to detect.
These blind spots show up quietly at first like higher frequency of small severity claims in freelance platforms, uninsured digital asset exposures hiding in commercial portfolios, or ESG-linked operational risks creeping into D&O policies.
And because these patterns don't immediately appear in traditional loss triangles or actuarial tables, they often remain invisible until renewal cycles are already impacted.
In fact, industry analyses show that emerging risk drivers typically remain “hidden” in underwriting systems for 9-18 months before they surface in ratios or reserving pressure.
That lag is enough to distort pricing, widen loss picks, and erode portfolio profitability.
A single overlooked variable can shift portfolio-level expected loss ratios by 2-4% points, forcing reactive pricing and mid-year reserve adjustments instead of proactive mitigation.
How does AI turn raw data into real-time early warning systems?
Let’s be honest.
Insurers aren’t short on data. Between submissions, broker notes, pricing sheets, and third-party risk scores, the pipelines are overflowing.
Yet when a new loss pattern starts forming, it still takes months before anyone spots it in the ratios.
The gap isn’t data; it’s detection speed.
That’s where AI changes the game. Here are three ways it does that:
It spots weak signals before they become losses
AI tools continuously scan through live submission data, claim notes, and portfolio trends to detect subtle changes, maybe it’s an uptick in small claims from one region, or a shift in policy language that hints at new exposure types.
A Deloitte analysis found that AI-driven anomaly detection reduces emerging-risk detection time by 20–30% compared to traditional data review cycles.
That’s exactly what Underwrite.AI’s contextual anomaly detection engine does, filtering noise from signal and surfacing underwriting-relevant anomalies in real time.
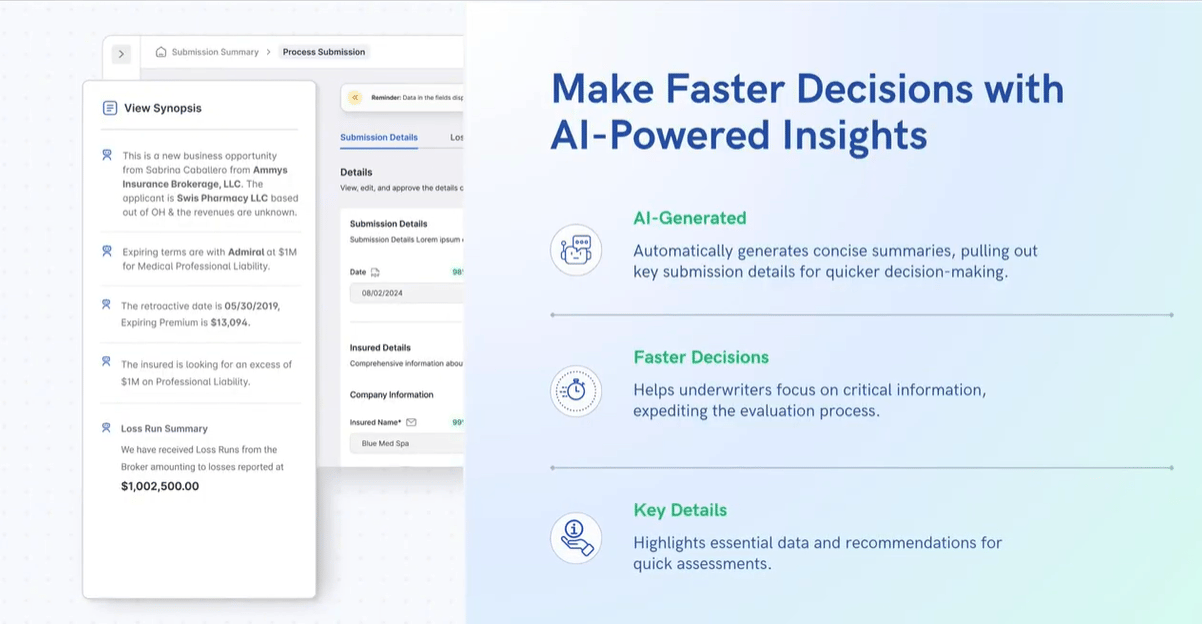
See Underwrite.AI in action
AI models can ingest external signals, cyber incident feeds, commodity prices, climate trends, or supply chain reports, and correlate them with your underwriting data.
For example, a rise in ransomware chatter on security forums might correlate with upcoming errors-and-omissions claims in your tech portfolio.
Or a regional drought signal could align with property submissions showing elevated fire risk.
These tools connect dots that human analysts can’t track fast enough, surfacing the kind of “weak correlations” that legacy models miss.
It turns static risk models into self-learning systems
Traditional risk models are like annual checkups. AI tools make them more like continuous monitoring, learning from every new claim, adjustment, and external variable.
McKinsey’s analytics benchmark shows that continuous model calibration can reduce portfolio volatility by up to 15% and shrink underwriting cycle times by nearly 25%.
Underwrite.AI’s adaptive feedback engine enables transforming one-off models into living systems that evolve with every transaction, keeping underwriting decisions both current and competitive.
In fact, “AI has reduced the average underwriting decision time of three to five days to 12.4 minutes for standard policies, while maintaining a 99.3% accuracy rate in risk assessment.”

Now that you’ve seen what’s possible with real-time detection, adaptive scoring, and contextual anomaly analysis…
The only question left is: will you wait for the next loss trend to show up in your ratios, or catch it before it hits?
See Underwrite.AI in action
Team Underwrite.In